Elice Group Releases Korean AI Training Datasets on Hugging Face
- Input
- 2026-01-14 09:22:14
- Updated
- 2026-01-14 09:22:14
Elice Group plans to support the revitalization of AI research and development at home and abroad by providing high-quality data suitable for training Korean artificial intelligence (AI) models, enabling researchers, developers, and companies to make broad use of it.
The newly released datasets consist of two types: the Korean FineWeb Education Dataset Demo and the Korean Web Text Educational Dataset, both designed to enhance the Korean-language performance of Large Language Model (LLM) systems in academic and educational domains.
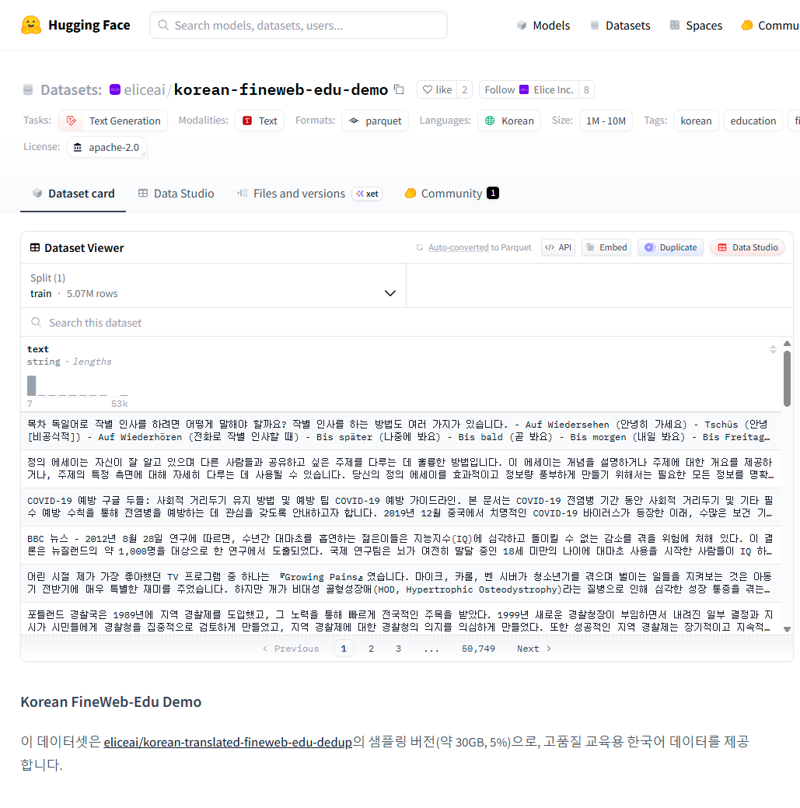
The Korean FineWeb Education Dataset Demo is a sample composed of 5% of the dataset korean-translated-fineweb-edu-dedup, which is a Korean translation of FineWeb Edu, an English educational web text corpus. It is designed to be used for training Korean LLMs in academic and educational domains and is provided to verify data characteristics and usability prior to large-scale training.
The original dataset for the demo, korean-translated-fineweb-edu-dedup, is a large-scale text dataset of about 190 billion (190B) tokens, equivalent to tens of millions of pages. When used together with multilingual data, it is large enough to be used for training a foundation model. Although the newly released Korean FineWeb Education Dataset Demo is only a 5% sample of this, it is still one of the largest high-quality open-source Korean datasets currently available.
The Korean Web Text Educational Dataset released alongside it was built by selecting only content from large-scale Korean web text that passed an educational value scoring process. It was constructed so that it can be used for training Korean AI models by evaluating factual accuracy, contextual consistency, and educational suitability.
The release of these datasets is based on Elice Group’s accumulated experience across AI infrastructure, model training, and deployment in educational and industrial settings. Through this release, Elice Group aims to lower the entry barriers to Korean AI research and to support the use of Korean AI models in education, research, and the public sector. The company also plans to accelerate the development of Korean-specialized AI services and solutions by linking these efforts with its capabilities in AI infrastructure, cloud, and data engineering.
Kim Suin, Chief Research Officer (CRO) at Elice Group, who led the construction of the datasets, said, “Data accessibility and quality are core factors in the advancement of AI technology,” adding, “Elice Group has built high-quality datasets that are easier for researchers, developers, and companies to use by applying criteria validated in actual model training and service environments.”
mkchang@fnnews.com Jang Min-kwon Reporter